Comment choisir le bon LLM ?
L'intelligence artificielle évolue à une vitesse vertigineuse. Chaque semaine, une nouvelle annonce promet des capacités qui détrônent la génération précédente. Face à ce rythme effréné, la première réaction de nombreuses entreprises est de vouloir intégrer systématiquement la dernière technologie disponible pour ne pas prendre de retard.
Pourtant, choisir un modèle d'IA ne devrait jamais être un réflexe conditionné par le marketing des éditeurs. La tentation de prendre systématiquement la solution la plus puissante pour s'assurer un résultat impeccable conduit presque toujours à un surdimensionnement coûteux. L'entreprise se retrouve alors à payer pour des capacités de raisonnement poussées que son usage réel ne nécessitera jamais, tout en alourdissant inutilement son infrastructure et en dégradant la latence de ses réponses.
Plus important encore : sélectionner un modèle n'est pas une décision ponctuelle. C'est un processus continu. Ce qui est considéré comme la "meilleure" solution aujourd'hui pour un cas d'usage précis ne le sera peut-être plus dans trois mois. Pour éviter les gaspillages et garantir une performance optimale sur le long terme, il est indispensable d'appliquer une méthode rationnelle. La toute première étape de cette approche consiste à définir précisément ce que l'IA va faire, en répondant à deux questions fondamentales : quel est son rôle, et dans quel domaine va-t-il évoluer ?
Définir le rôle : la mécanique de l'IA
La première étape consiste toujours à se poser cette question : le rôle, c'est la nature même de l'interaction attendue avec l'utilisateur ou le système. Est-ce un simple chatbot ? Un agent autonome ? Un outil d'extraction pure ?
- Le Chatbot de premier niveau : Si le rôle est d'interagir avec des utilisateurs pour répondre à des questions fréquentes, l'IA a surtout besoin d'être réactive, fluide et de bien comprendre l'intention générale.
- L'Agent autonome : Là, les attentes changent drastiquement. Il ne fait pas que parler, il agit. Concrètement, il doit être capable de planifier des étapes, de choisir la bonne API à appeler selon la situation et de maintenir le cap sur un objectif final sans se disperser.
- L'Extracteur de données : Dans ce cas de figure, il faut être très clair : l'IA n'a strictement aucun besoin d'être créative. Sa seule mission est d'ingérer du texte brut pour le ressortir sous un format strict (comme du JSON), de manière répétitive et sans ajouter le moindre commentaire.
Définir le domaine : le contexte et le niveau de risque
Ensuite, il y a le domaine d'application. C'est à ce moment-là qu'il est nécessaire de regarder le niveau de tolérance aux erreurs en face. On n'attend pas le même niveau d'exigence d'une IA selon le secteur d'activité dans lequel elle est déployée.
- Tolérance zéro (Santé, Légal, Finance) : Si vous l'utilisez dans le domaine de la santé pour aider à l'analyse de dossiers patients, la moindre erreur factuelle est inacceptable. Le modèle doit manipuler un jargon médical pointu et le danger principal à éviter est l'hallucination. Inutile de préciser les conséquences si l'IA invente un symptôme ou un dosage. C'est la même logique dans le domaine légal, où l'IA doit comprendre les subtilités d'un contrat et être irréprochable sur la véracité des sources. Dans le domaine financier, c'est la précision absolue des chiffres et le respect des normes de compliance qui priment.
- Tolérance élevée (Marketing, RH, Créativité) : À l'inverse, si vous l'utilisez pour générer des idées de campagnes marketing, rédiger des brouillons d'emails ou résumer des réunions internes, la marge de manœuvre est beaucoup plus grande. Une tournure de phrase imparfaite ou une idée légèrement décalée n'aura aucun impact négatif sur l'entreprise.
L'impact sur le choix du modèle : C'est vraiment la combinaison de ce rôle et de ce domaine qui va dicter vos besoins. Un agent autonome déployé dans le domaine médical justifiera pleinement l'utilisation d'un modèle très lourd, coûteux et gourmand en ressources. Mais si vous mettez en place un chatbot basique pour un site e-commerce, il est fortement déconseillé d'utiliser ce même modèle de pointe : ce serait un gaspillage total. Un petit modèle léger fera le travail attendu, et il est pratiquement garanti qu'il le fera souvent mieux en termes de fluidité et de coût.
Décryptage des métriques publiques : Benchmarks et Leaderboards
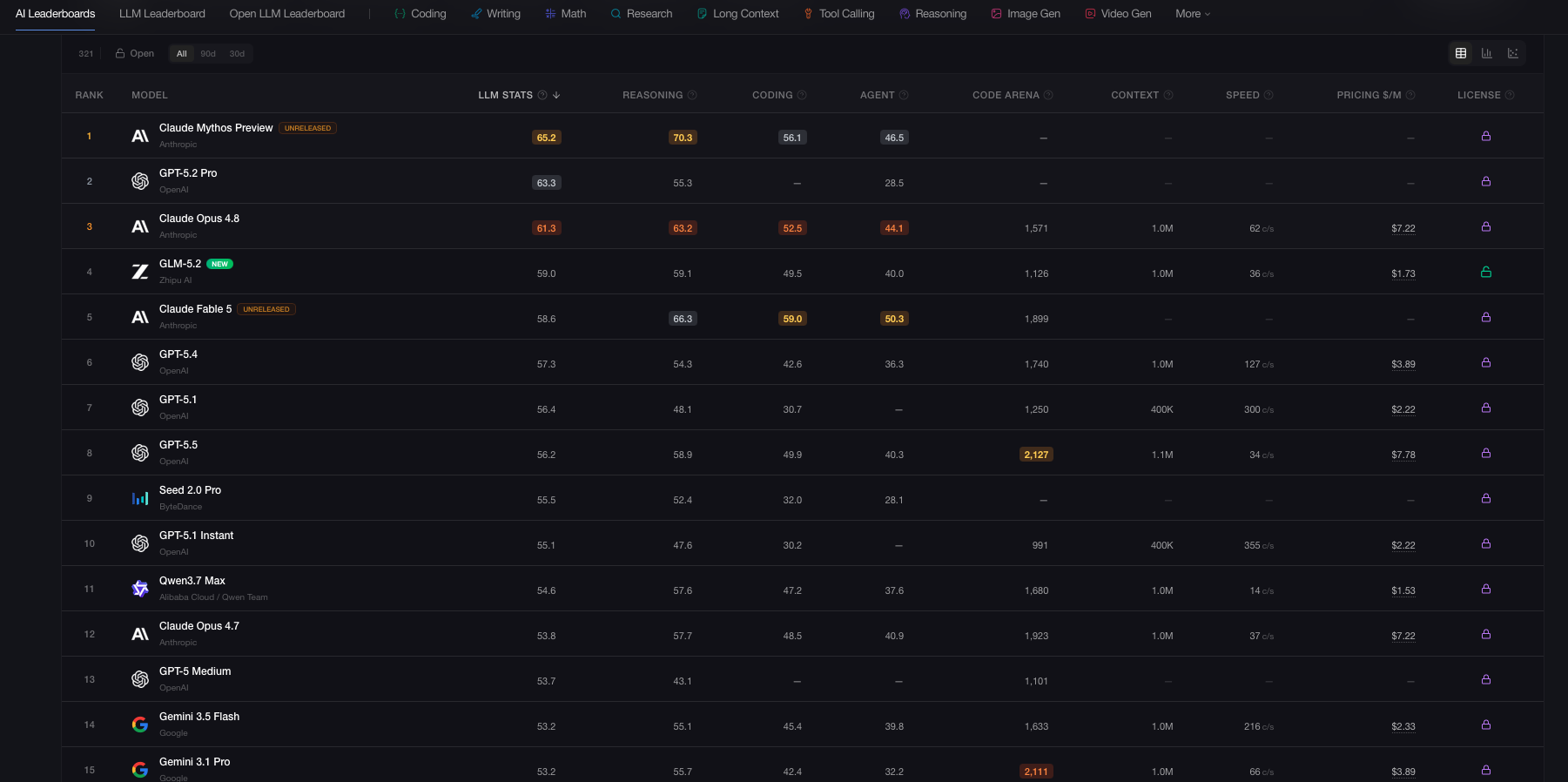 LLM Stats AI Leaderboards.
LLM Stats AI Leaderboards.
C'est ici que les choses deviennent vraiment intéressantes. Une fois ce contexte entièrement cadré, il est temps de rentrer dans le vif du sujet : comment évaluer concrètement ces modèles grâce aux bonnes métriques. La plateforme que j'utilise est llm-stats.com (ou des alternatives comme Artificial Analysis). Pour utiliser ces outils correctement, il faut d'abord comprendre comment ils fonctionnent.
Il est crucial de faire la distinction entre deux concepts souvent confondus. Un benchmark est un test standardisé spécifique. Par exemple, le MMLU est un benchmark qui pose des questions à choix multiples sur 57 matières académiques, tandis que HumanEval demande au modèle de coder des fonctions Python précises. Un leaderboard, quant à lui, est un tableau de classement qui agrège les résultats de plusieurs benchmarks pour vous offrir une vue d'ensemble.
L'erreur à éviter est de choisir un modèle en regardant simplement le premier nom du classement général. L'idéal est plutôt d'utiliser les leaderboards comme un entonnoir. Grâce à votre définition préalable du rôle et du domaine, vous pouvez cibler les classements spécifiques pour identifier une liste de trois ou quatre candidats potentiels, tout en gardant à l'esprit que ces tests sont réalisés en laboratoire, souvent en anglais, et ne reflètent pas la réalité de vos données d'entreprise.
Voici comment lire et utiliser les différentes catégories de classements disponibles.
Les classements par capacité (By Capability)
Cette section agrège des benchmarks qui évaluent la mécanique intellectuelle brute du modèle.
- Chat : Évalue la fluidité conversationnelle, la compréhension des nuances et l'évitement des réponses robotiques.
- Reasoning : Regarde des benchmarks mathématiques et logiques. Rappelons que ce score est crucial si votre rôle nécessite des déductions complexes à partir de règles strictes.
- Coding : Mesure la capacité à écrire du code fonctionnel dès le premier essai, sans erreurs de syntaxe, ainsi qu'à comprendre du code existant pour le déboguer.
- Tool Calling : Évalue la précision du modèle pour générer du JSON structuré et déclencher des fonctions externes au bon moment. Indispensable pour tout agent autonome.
- Long Context : Vérifie si le modèle peut retrouver une information précise (le test de "l'aiguille dans une botte de foin") cachée au milieu d'un document de 50 000 mots ou plus.
- Writing : Mesure la qualité rédactionnelle, la richesse lexicale et le respect des consignes de style.
- Research : Évalue la capacité à synthétiser de multiples sources d'information complexes de manière cohérente.
Les classements par modalité (By Modality)
Ces classements évaluent la polyvalence du modèle lorsqu'il sort du simple texte.
- Image Understanding : Le modèle doit analyser des graphiques, des schémas ou des photos pour répondre à une question.
- Image / Video Generation : Classe les modèles sur leur capacité à générer des images ou des vidéos fidèles à un prompt complexe, en évaluant la cohérence spatiale et temporelle.
- Speech Generation / Transcription : Évalue le naturel d'une voix de synthèse ou mesure le taux d'erreur mot par mot lors de la conversion d'audio.
- Computer Use : Un domaine émergent qui teste si le modèle peut comprendre une interface graphique, bouger un curseur virtuel et cliquer sur des boutons pour accomplir une tâche. Son potentiel est fascinant pour les années à venir.
Les classements par industrie (By Industry)
C'est ici que votre travail de définition du domaine prend tout son sens. Ces leaderboards ne testent pas l'intelligence générale, mais la maîtrise d'un jargon et de normes spécifiques.
- Legal : Basé sur des examens de barreau, des contrats types et de l'analyse de jurisprudence pour mesurer la rigueur juridique.
- Healthcare : Évalue le modèle sur des questions cliniques et de la littérature médicale scientifique. Le taux d'erreur ici est le critère numéro un à observer.
- Finance & Accounting : Teste la capacité à lire des bilans comptables, à calculer des ratios financiers et à comprendre les réglementations.
L'indicateur stratégique : le coût. Au-delà des performances pures, il faut également prêter attention à ce que donnent ces plateformes : le prix par million de tokens. Savoir qu'un modèle est excellent sur le leaderboard "Legal" est une bonne chose, mais savoir combien coûte une requête sur ce modèle par rapport à celui qui est juste en dessous change totalement la donne. Vous pouvez ainsi écarter d'emblée un candidat dont le score n'est que légèrement supérieur, mais dont le coût à l'appel est trois fois plus élevé.
Construire et exécuter son propre benchmark technique
En croisant le rôle, le domaine, le leaderboard spécifique et le coût, on arrive généralement à une liste très restreinte de deux ou trois modèles pertinents. Pourtant, il ne faut pas s'arrêter là. Les benchmarks publics ne suffisent pas à garantir le succès en production. L'étape la plus déterminante, celle qui fait la différence entre un projet qui fonctionne et un qui échoue, reste de créer votre propre benchmark d'entreprise. Les tests standardisés ne reflétant pas la réalité de vos données, vous devez construire un protocole d'évaluation reproductible et automatisé.
Si des outils traditionnels sont excellents pour des métriques basiques (comme LLM Evaluation Harness), ils montrent très vite leurs limites face à la nature générative des LLM. Pour évaluer la qualité réelle d'un chatbot ou d'un agent, il est préférable de se tourner vers des frameworks d'évaluation modernes comme DeepEval (développé par Confident AI), qui est spécifiquement conçu pour mesurer les comportements complexes des LLM.
La constitution du jeu de données d'entreprise
La première étape technique consiste à créer votre corpus de test. Rappelons-le : il ne s'agit pas de lancer le modèle au hasard, mais de constituer un ensemble d'exemples concrets issus de votre historique. Vous rassemblez des questions clients réelles, des extraits de contrats ou des tickets support, et vous associez chaque entrée à la réponse idéale (le "ground truth") ou au contexte de référence.
Avec ce type de framework, ces données sont formatées en objets informatiques simples, ce qui permet de stocker non seulement la question et la réponse attendue, mais aussi le contexte RAG (Retrieval-Augmented Generation) qui a été fourni au modèle, ou même les outils qui étaient à sa disposition.
L'évaluation par la conformité (LLM-as-a-Judge)
C'est une technique redoutablement efficace : le "LLM-as-a-Judge". Plutôt que d'essayer de coder des règles complexes pour vérifier si une phrase est correcte, vous utilisez un modèle très performant (comme Claude 4.7) pour évaluer les réponses de vos candidats selon des critères stricts.
Ils intègrent des métriques d'évaluation prêtes à l'emploi qui sont extrêmement difficiles à coder soi-même. Par exemple, la métrique d'Hallucination va demander au modèle juge de vérifier si chaque affirmation de la réponse du candidat est factuellement soutenue par le contexte fourni. La métrique de Pertinence de la Réponse va évaluer si la réponse est bien centrée sur la question initiale, pour éviter que le modèle ne se perde dans des digressions.
Les métriques spécifiques aux architectures modernes (RAG)
La majorité des chatbots d'entreprise aujourd'hui utilisent une architecture RAG (le modèle lit des documents internes avant de répondre). Or, les benchmarks publics ne testent pas cela. C'est pourquoi ces frameworks proposent des métriques natives particulièrement utiles pour ce cas d'usage.
Vous pouvez évaluer la Fidélité : le modèle a-t-il utilisé les documents récupérés, ou a-t-il ignoré la source pour inventer une réponse ? Vous pouvez aussi mesurer la Pertinence Contextuelle, qui évalue si votre système de recherche de documents a bien remonté les bons morceaux de texte pour aider le modèle à répondre. Pour faire simple : si vous changez de modèle LLM mais que votre score de pertinence contextuelle chute, le problème ne vient peut-être pas du modèle, mais de la façon dont il interprète les documents récupérés.
La création de métriques sur mesure
Même avec des métriques intégrées, il est évident que votre entreprise a des règles spécifiques. C'est là qu'interviennent des fonctionnalités comme GEval. Elle permet de créer une métrique personnalisée en langage naturel.
Par exemple, si vous avez défini un rôle dans le domaine légal, vous pouvez écrire une instruction pour votre juge : "Évalue si la réponse cite au moins une jurisprudence, si le ton est formel, et si elle contient un désistement de responsabilité. Attribue un score de 1 si une condition manque, ou 0 si tout est présent." Le framework se charge de structurer cette consigne, de l'envoyer au modèle juge et de normaliser le score. C'est d'une efficacité redoutable.
L'intégration dans le cycle de développement (CI/CD)
L'avantage majeur de cette approche technique, et c'est son plus grand atout pour les directions techniques, c'est qu'elle transforme l'évaluation d'un LLM en un test logiciel classique. Vous écrivez vos cas de test une seule fois, et vous pouvez les exécuter automatiquement via des outils d'intégration continue.
Cela signifie que si vous décidez de changer le prompt système de votre chatbot, ou si un nouveau modèle moins cher sort sur le marché, vous n'avez pas à tout relire manuellement. Vous lancez votre suite de tests automatisée. Si le nouveau modèle fait baisser votre score de non-hallucination en dessous du seuil que vous avez défini, le test échoue et vous savez immédiatement que ce modèle n'est pas prêt pour la production.
La surveillance du modèle en production
Même après avoir trouvé le modèle parfait, passé les benchmarks maison et validé l'arbitrage coût/performance, il faut garder en tête que le travail n'est pas terminé. Contrairement à un logiciel classique basé sur des règles strictes, un LLM est par nature probabiliste. Son comportement va évoluer en fonction des données qu'il reçoit. Déployer un modèle sans le surveiller, c'est s'exposer à des dérives silencieuses qui peuvent ruiner votre retour sur investissement en quelques semaines.
Anticiper les dérives de performance
Ce phénomène, que l'on nomme la "dérive de données" (data drift), est la première raison pour laquelle un modèle bien évalué finit par décevoir en production. Si vous utilisez une architecture RAG, la base de documents internes de votre entreprise va s'enrichir avec de nouvelles réglementations, de nouveaux produits ou de nouvelles procédures. Le modèle, lui, reste identique. Les réponses qu'il générait justement en mars peuvent devenir obsolètes ou franchement fausses en juin.
Il est également fréquent de constater que le comportement des utilisateurs évolue. Lors de vos tests, vous aviez utilisé des requêtes représentatives de l'historique. En production, les utilisateurs finaux vont trouver des failles, poser des questions sous des angles inédits ou essayer de détourner le système. Il faut mettre en place un système de feedback continu pour repérer ces nouveaux cas d'usage et les réintégrer dans votre benchmark maison.
Surveiller les coûts et la latence en temps réel
Un modèle qui semble rentable sur le papier peut devenir un gouffre financier en production. Il est donc indispensable de monitorer la consommation de tokens en temps réel. Une hausse soudaine du coût moyen par conversation peut indiquer plusieurs problèmes : le modèle fait des boucles de raisonnement inutiles, il récupère trop de contexte dans votre base de données, ou pire, des utilisateurs malveillants tentent de saturer votre API.
La latence doit également être suivie sous forme de graphiques. Si le temps de réponse de votre chatbot augmente progressivement de 500 millisecondes à 2 secondes sur quelques mois, c'est souvent le signe que le fournisseur de l'API cloud est sous tension ou que votre infrastructure locale nécessite un redimensionnement.
La sécurité et le contrôle des hallucinations
Un LLM en production est une porte d'entrée vers vos systèmes d'information. Il est impératif d'inclure la détection des tentatives de "prompt injection" dans la surveillance, où un utilisateur essaie de manipuler le modèle pour contourner ses consignes initiales (lui faire révéler son prompt système ou ignorer ses filtres de sécurité).
Il faut également monitorer les hallucinations en direct. Cela peut se faire en intégrant une couche de vérification légère (un petit modèle rapide et peu cher) qui valide en arrière-plan que la réponse générée contient bien des faits présents dans les documents de référence, avant de l'afficher à l'utilisateur.
Les outils d'observabilité (LLMOps)
Pour ne pas perdre le contrôle, l'idéal est de s'équiper d'outils d'observabilité spécifiques à l'IA, souvent regroupés sous le terme LLMOps. Des plateformes comme LangSmith, LangFuse ou Arize Phoenix s'intègrent directement dans votre code. Elles permettent d'enregistrer chaque interaction (le prompt de l'utilisateur, le contexte récupéré, la réponse du modèle, le temps d'exécution et le coût exact).
Ces outils offrent une interface pour retracer exactement pourquoi une conversation a déraillé et identifient le point de bascule. En reliant ces outils de surveillance à vos benchmarks automatisés, il est fortement conseillé de mettre en place des alertes : si le score de fidélité mesuré en production passe en dessous de 90%, une notification est envoyée à votre équipe technique pour investiguer.
Faire du choix du modèle un processus continu
C'est ici que réside la véritable valeur de toute cette méthodologie. Le marché des LLM évolue si vite que le modèle optimal d'aujourd'hui ne le sera plus nécessairement dans deux mois. En couplant une surveillance rigoureuse en production avec la reproduction régulière de votre processus de choix (de l'analyse des leaderboards à l'exécution de vos benchmarks maison), vous transformez une décision statique en un cycle d'optimisation dynamique.
Dès qu'un nouveau modèle plus performant ou moins cher apparaît sur le marché, vous n'avez pas besoin de recommencer à zéro. Vous le soumettez simplement à votre pipeline d'évaluation existant avec vos données réelles. C'est en reproduisant cette mécanique de manière itérative que l'on s'assure de posséder, à chaque instant, le modèle le mieux adapté à la réalité de l'entreprise.
Conclusion
En résumé, choisir un LLM pour son entreprise ne doit plus être un pari technologique guidé par l'actualité de l'IA. La puissance brute d'un modèle n'est qu'une variable parmi d'autres, et elle est extrêmement éphémère.
En suivant cette méthode étape par étape, vous éliminez les gaspillages. Vous commencez par définir le métier et le domaine pour éviter le surdimensionnement. Vous utilisez les leaderboards publics non pas pour choisir un gagnant absolu, mais pour écarter les incompétents et repérer les candidats potentiels. Vous créez ensuite votre propre protocole d'évaluation rigoureux avec des frameworks spécialisés pour mesurer la vérité sur vos propres données. Enfin, vous assurez la pérennité de votre système en surveillant le modèle en production et en répétant ce cycle d'évaluation au fil des sorties des nouveaux modèles.
C'est seulement en appliquant ce raisonnement systématique et itératif que vous trouverez, et maintiendrez, le véritable point d'équilibre : le modèle le plus adapté, le plus fiable, et le plus rentable pour votre entreprise.
Liens Utiles
Pour approfondir vos connaissances et explorer des outils avancés, voici quelques ressources :
- RAG Evaluation A Step-by-Step Guide with DeepEval
- Deepchecks Continuous Validation for AI & ML: Testing, CI & Monitoring
- Phoenix AI Observability & Evaluation
Ma recommandation musicale du jour : à écouter sans modération !
Écouter sur YouTube